هل التعلّم العميق عامل تغيير في تحليلات التسويق؟
تتخذ الشركات بالفعل قرارات تسويق معقّدة باستخدام البيانات والتحليلات. فهل سيمكّن التعلّم العميق من القفز إلى الأمام — أم أنه مجرّد مكاسب هامشية؟

غلين أوربان، أرتيم تيموشنكو، بارامفير ديلون، جون آر هاوزر
يحقق التعلم العميق Deep learning نتائج رائعة في تطبيقات الذكاء الاصطناعي. مثلاً، تترجم سيري Siri من أبل Apple الصوت البشري إلى أوامر حاسوبية تتيح لمالكي الآيفون iPhone الحصول على إجابات عن أسئلة وإرسال الرسائل والتنقل في طريقهم إلى مواقع غير معروفة ومنها. فالقيادة المؤتمتة Automated driving تُمكّن الأشخاص اليوم من الانتقال من دون استخدام أيديهم على الطرق السريعة، وستفعل الشيء نفسه في نهاية المطاف في شوارع المدن. وفي علم الأحياء ينشئ الباحثون جزيئات جديدة للاستخدام كأدوية قائمة على الحمض النووي DNA.
وبالنظر إلى هذا النشاط كله الجاري من خلال التعلم العميق، يتساءل كُثر كيف ستغير الأساليب الكامنة مستقبل التسويق. وإلى أي مدى ستساعد هذه الطرق الشركات على تصميم منتجات وخدمات جديدة مربحة لتلبية احتياجات العملاء؟
إن التكنولوجيا التي تدعم التعلم العميق قادرة بشكل متزايد على تحليل قواعد البيانات الكبيرة للأنماط والتبصرات. وليس من الصعب تخيل يوم تتمكن فيه الشركات من دمج مجموعة واسعة من قواعد البيانات لتمييز ما يريده المستهلكون، وتمتاز بمزيد من التعقيد والقوة التحليلية، ثم الاستفادة من هذه المعلومات لصالح السوق. مثلاً، ربما لا يمر وقت طويل قبل أن يتلقى مستهلكون، تحدد هويتهم تقنية التعرف على الوجه أثناء تسوق البقالة، قسائم فردية بناءً على سلوك الشراء السابق. وفي المستقبل قد تُصمَّم الإعلانات بشكل فردي لجذب المستهلكين ذوي الشخصيات المختلفة، وقد تُقدَّم في الوقت الفعلي في حين يشاهد المستهلكون يوتيوب YouTube. ويمكن أيضاً استخدام التعلم العميق في تصميم منتجات تلبية الاحتياجات الشخصية للمستهلكين، يمكن بعد ذلك إنتاجها وتسليمها من خلال أنظمة الطباعة الثلاثية الأبعاد 3D printing المؤتمتة.
وستحاول أنواع مختلفة من المؤسسات تسخير قوى التعلم العميق بطرقها الخاصة. وقد يستخدمها صانع للسيارات لاستهداف عملاء جدد، أو تجديد عملية الشراء، أو تحسين ميزات المنتجات التي تريدها مجموعة محددة من المشترين. وقد يعتمد الأمر على مجموعة كبيرة من البيانات ذات الصلة لفعل ذلك كله، بما في ذلك بيانات إصلاح السيارات، وتقييمات المستهلكين لجودة المركبات وموثوقيتها، وتسجيلات السيارات، والمنشورات على تويتر Twitter المتعلقة بشراء السيارات وتجربة المستخدمين، ومنشورات فيسبوك Facebook التي تعرض أشخاصاً مع سياراتهم، وملفات بيانات إدارة علاقات العملاء لدى الشركات المصنعة، والنقرات عبر الإنترنت. وفي الوقت نفسه، يمكن لأي مصرف الاستفادة من التعلم العميق لتطوير منتجات أو خدمات جديدة وتخصيص عروضه الترويجية. ومن خلال تحليل البيانات المتعلقة بتواريخ قروض العملاء، ومعاملات بطاقات الائتمان، وسجلات حسابات الادخار والحسابات الجارية، والنقرات على المواقع الشبكية، وسلوك مواقع التواصل الاجتماعي، وتقييمات المنتجات، وتواريخ البحث، استطاع أن يكتسب تبصرات في الأشياء التي يقدرها بعض العملاء. فما هي الأشياء التي يريدها أكثر من غيرها الخبراء البالغون من العمر 40 سنة والمقيمون في أحياء حضرية من بطاقة ائتمان؟ هل يفضلون مكافآت السفر أو حماية المشترين أو استرداد النقود أو الأسعار المنخفضة للفائدة؟
بالتأكيد، يستخدم كثير من المديرين بالفعل التحليلات مع نماذج إحصائية وقواعد بيانات مركزة لمتابعة أداء العلامة التجارية وجدولة العروض الترويجية واتخاذ قرارات الإنفاق. فكيف يختلف التعلم العميق، إذاً؟ هل هي قفزة أساسية إلى الأمام، أو أنها ستعزز ببساطة المكاسب الهامشية؟ في هذا الموضوع، سنبحث في هذه الأسئلة عمّا يتعلق بدراسة أجريناها وشملت بطاقات الائتمان. إضافة إلى ذلك، سننظر في ما تقترحه هذه الأبحاث حول الاتجاه المستقبلي للتحليلات.
وعلى الرغم من أننا لا نزال في الأيام الأولى للتعلم العميق، فليس من المبكر طرح الأسئلة التالية: ما الذي سيعرضه على الشركات مقارنة بما اعتاد عليه مديرو أساليب التحليلات الحالية؟ هل يمكن أن يقدم توقعات أفضل، وإذا لم يكن الأمر كذلك، كيف يمكن تحسينه؟ وما هي أنواع الاستثمارات في البيانات والتكنولوجيا التي يتعين على الشركات عملها في مجال التعلم العميق للاستفادة من أحدث القدرات وأقواها؟ تشير أبحاثنا إلى وجود أسباب للتفاؤل، على الرغم من أن التعلم العميق ربما لا يؤدي إلى مكاسب كبيرة في دقة التوقع على الفور أو في كل مكان.
تجربتنا
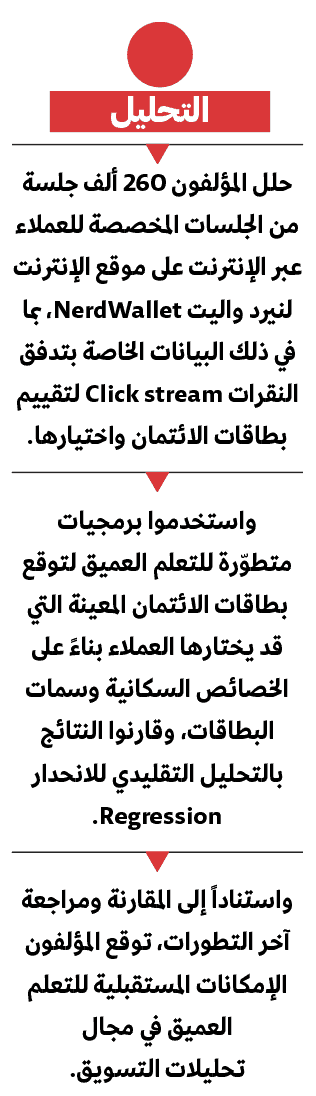
لمقارنة التعلم العميق بالأساليب التقليدية لتحليلات التسويق، درسنا قاعدة بيانات كبيرة من تدفقات النقرات Click streams، والخصائص السكانية Demographics، والاطلاع على الإعلانات المتعلقة بسوق بطاقات الائتمان من نيرد واليت NerdWallet، وهي جهة كبرى موردة لبطاقات الائتمان عبر الإنترنت، ومقرها سان فرانسيسكو. وأردنا معرفة ما إذا كان في مقدور نموذج التعلم العميق المتعدد المستويات توقع خيارات بطاقات الائتمان بشكل أدق من النماذج التقليدية.
وتمثّل القدرة على توقع خيار العميل الخطوة الأولى نحو تحسين القرارات التي تدخل في تصميم المنتج، وتخصيص الموارد الخاصة بالوسائط، وكيفية الترويج للمنتج (في هذه الحالة، بطاقة الائتمان)، ومن يجب استهدافه. وتتطلب معرفة ما يقدّره الأفراد أكثر من غيره تجريباً ونمذجة توقعية للخيارات. وحدسنا أن التعلم العميق قد يوفر صورة أوضح ومفيدة أكثر من نموذج الانحدار البسيط Regression model. لاختبار هذا الافتراض، نظرنا في عمليات اختيار بطاقات الائتمان لـ260 ألف فرد، مع مراعاة 25 عاملاً من عوامل الخصائص السكانية (بما في ذلك الأشياء الواضحة، مثل العمر والنوع ودخل الأسرة، وفئات أكثر تفصيلاً مثل النتيجة الائتمانية والبطاقات التي يمتلكها المستهلك حالياً والرمز البريدي)؛ و132 سمة لكل بطاقة (مثل سعر الفائدة، سواء أعرضت البطاقة نقاط مكافأة أم أميال سفر أم استرداد نقود، ورسوم العضوية السنوية وتحويلات الرصيد)؛ والبطاقات التي يطلبها كل شخص.
ويجمّع موقع الإنترنت نيرد واليت المعلومات ومراجعات الخبراء حول نحو ألفي بطاقة ائتمان مختلفة من مئات المصارف حتى يتمكن العملاء من أن يقارنوا بين الميزات ويقرروا ما هو مهم لهم. وتُسجَّل المنتجات التي يشاهدها المستخدمون خلال جلساتهم عبر الإنترنت. وتلاحظ نيرد واليت أيضاً عندما ينقر شخص ما لمعرفة مزيد من التفاصيل أو يختار بطاقات معينة للمقارنة. وبعد أن يقرر المستخدمون بطاقة الائتمان التي يريدونها من موقع نيرد واليت، يُوجَّهون إلى موقع المصرف لإكمال الطلب. ولأغراض دراستنا، فقد تعاملنا مع هذا الإجراء كمؤشر إلى الخيار النهائي.
وباستخدام قاعدة البيانات الخاصة بنيرد واليت، قارنا ثلاثة نماذج للخيار. (لمزيد من التفاصيل، انظر: ملاحظة تقنية للمحللين). وكان النموذج الأول عبارة عن انحدار خطي Linear regression اعتيادي بالخيار كدالة Function تتعلق بالخصائص السكانية العائدة إلى المستخدم الفردي وسمات البطاقة. وكان لكل متغير Variable أثر مباشر بسيط في الخيار من خلال معادلة واحدة، مع عدم وجود تفاعلات بين المتغيرات. مثلاً، إذا كان معاملاً Coefficient يساوي 0.058 ضعف عدد أميال المكافأة الممنوحة لكل ألف دولار يصرفها الفرد قد يساعد على توقع ما إذا كان المستهلك سيختار البطاقة الخضراء من أميريكان إكسبرس American Express Green Card.
وكان النموذج الثاني نمذجة تعلم عميق بسيط Deep learning model، يتضمن طبقات مخفية بين متغيرات الإدخال واحتمال الخيار. ويرتبط كل متغير إدخال (مثلاً، أميال المكافأة) بمتغير كامن، يرتبط بدوره باحتمال الخيار. ولم تُحدَّد المتغيرات الكامنة على وجه التحديد؛ فهي، بدلاً من ذلك، مزيج من متغيرات الإدخال عند المستوى الأول. وهي ترتبط بمتغيرات كامنة أخرى في مستوى النمذجة التالي، والمتغيرات الكامنة اللاحقة هي مجموعات من المتغيرات الكامنة الأخرى. وقد يبدو هذا معقداً بشكل غير ضروري، لكن ربط المتغيرات الكامنة بين الطبقات المخفية هو ما يمنح التعلم العميق قدرته (وحتى اسمه). وكانت لنمذجتنا ثلاثة مستويات. ورصدت الطبقة الأولى آثار السمات الملاحَظة للبطاقات والخصائص السكانية في مجموعة من المتغيرات الكامنة، ثم نظرنا في أثر تلك المتغيرات الكامنة في الطبقات اللاحقة من المتغيرات الكامنة. ومع وجود ثلاث طبقات مخفية تسمح بالتفاعلات المعقدة والجوانب اللاخطية Nonlinearities، كان الأمل بأن نتمكن من أن نتوقع خيار البطاقة بشكل أدق.
 1For further information, see I. Goodfellow, Y. Bengio, and A. Courville, “Deep Learning” (Cambridge, Massachusetts: MIT Press, 2015); A. Géron, “Hands-On Machine Learning With Scikit-Learn and TensorFlow” (Sebastopol, California: O’Reilly Media, 2017); and R.S. Sutton and A.G. Barto, “Reinforcement Learning: An Introduction” (Cambridge, Massachusetts: MIT Press, 2018).
1For further information, see I. Goodfellow, Y. Bengio, and A. Courville, “Deep Learning” (Cambridge, Massachusetts: MIT Press, 2015); A. Géron, “Hands-On Machine Learning With Scikit-Learn and TensorFlow” (Sebastopol, California: O’Reilly Media, 2017); and R.S. Sutton and A.G. Barto, “Reinforcement Learning: An Introduction” (Cambridge, Massachusetts: MIT Press, 2018).
وكانت نمذجتنا الثالثة بمثابة تعزيز لنمذجة التعلم العميق البسيط، إذ كانت المقاييس التابعة (المعتمدة)Dependent measures هي احتمال الخيار والبطاقات المحددة التي أخذها المستهلكون بعين الاعتبار في خيارهم النهائي. وأخذنا بالاعتبار المعلومات التفصيلية المتعلقة بعملية الشراء وبطاقات الائتمان الأخرى التي نظر فيها الأشخاص (استناداً إلى تدفقات نقراتهم). وبإدخال هذه الخطوة الإضافية من النظر إلى عملية الشراء، اعتقدنا أننا قد نحسّن من دقة توقعات الخيار لدى النمذجة الأساسية من التعلم العميق.
ما وجدناه
بناءً على تحليلنا، تمكنت النمذجتان اللتان تعتمدان على التعلم العميق من توقع خيارات بطاقات الائتمان بدقة أكبر من النهج التقليدي. (انظر: كيف يمكن للتعلم العميق أن يتفوق في الأداء على تحليلات التسويق التقليدية). ولكن التحسينات لم تكن كبيرة كما كنا نتوقع.
لقد بلغ معدل دقة نمذجة الانحدار البسيط %70.5، ما يعني أن في %70.5 من الحالات، تمكنا من أن نتوقع بشكل صحيح البطاقة التي قد يطلبها مستهلك معين وتلك التي لن يطلبها. وكان نموذج التعلم العميق البسيط أدق قليلاً، عند %71.7، وكان للنموذج الأكثر تطوراً معدل دقة بلغ %73.
لقد اعتقدنا أن إضافة طبقات كامنة قد تؤدي إلى مزيد من التحسينات الكبيرة. ولكن توقعاتنا ربما كانت مبالغاً فيها. فنماذج الانحدار الخطّيِّ المصممة جيداً والمُحسَّنة بالتجربة قد تكون قوية ودقيقة. وأتاحت المقاييس الكثيرة، أي المقاييس الكثيرة للخصائص السكانية وسمات البطاقة، توقعات جيدة من خلال النهج التقليدي.
التكاليف والمنافع
إذاً، ماذا أخبرتنا دراستنا عن إمكانات التعلم العميق؟ هل من المنطقي بالنسبة إلى مؤسسات التسويق أن تستثمر في التكنولوجيا وتطوير القدرات الأساسية الآن، بالنظر إلى مدى صغر التحسينات في توقع الخيار؟ في رأينا، من غير المرجح أن تحقق المكاسب الصغيرة في الدقة التوقعية لما هو ممكن باستخدام البيانات التقليدية عوائد عالية بما يكفي في معظم الحالات لتبرير استثمارات كبيرة في تطوير التعلم العميق. وقبل مجرد الغوص في الأمر، تحتاج المؤسسات إلى النظر إلى ما وراء المكاسب المحتملة والنظر في تحديات التنفيذ وتكاليفه.
ويتلخص عيب كبير في التعلم العميق في صعوبة تحديد المتغيرات التي توجه أكبر استجابة. فهل كانت مستويات مكافآت السفر لبطاقات الائتمان أو الأسعار المنخفضة للفائدة صاحبة الأثر الأكبر في خيار المستهلك؟ نظراً لأن المتغيرات تُعالَج من خلال العديد من الطبقات الكامنة التي تؤثر في الخيار، فمن الصعب قياس أثر عامل واحد. ويمكننا محاكاة أثر التغييرات في متغير واحد، لكن الأثر يعتمد على مستويات المتغيرات الأخرى كلها المستخدمة في الهيكل المعقد للنموذج. وقد يكون من الصعب ربط الأحكام البديهية لمديري التسويق بنتائج النموذج، وهذا سيجعل التنفيذ صعباً.

وهناك عوامل أخرى يجب مراعاتها. هناك تكاليف تكنولوجيا التعلم العميق والموظفين اللازمين لتنفيذها وتكاليف إضافية للبيانات قد تدعو الحاجة إلى تكبدها. وأخيراً، حتى مع الحواسيب السريعة اليوم، تحتاج نمذجات التعلم العميق إلى كميات هائلة من الطاقة الحاسوبية وقد تشهد أوقات تشغيل طويلة. ويصبح ذلك قيداً حقيقيّاً إذا كان التنفيذ مطلوبا فورا في الوقت الفعلي Real-time. وتكمن الحقيقة في معظم الحالات في عدم إمكانية تقديم حجة قوية لصالح التعلم العميق كبديل للتحليل التقليدي للبيانات إلا إذا استطاعت المكاسب المتواضعة في التوقع أن تؤدي إلى تقليل كبير في التكاليف أو فرص كبيرة في الأرباح.
ومع ذلك، لا نزال نعتقد أن فرص التعلم العميق مبشرة في بعض السياقات. فكما لاحظنا، يتميز التعلم العميق بميزات كبيرة مقارنة بتحليل الانحدار التقليدي لتحليل قواعد البيانات «الغنية» التي تتضمن صوراً وبيانات غير عددية. وقد تتضمن البيانات الغنية محتوى يولّده المستخدم (مثل المراجعات على أمازون Amazon، والمنشورات على إنستغرام، والمنشورات على فيسبوك، والتعليقات على المواقع الشبكية للشركات)، وقد تكون القيمة المحتملة لهذه البيانات كبيرة. وعلى الرغم من أن موقع نيرد واليت يحتوي على بيانات تفصيلية عن الأبحاث والمنتجات، فإنه لم يرتقِ إلى مستوى البيانات الغنية، لذلك لم تُفعَّل الميزات. وربما حسن وجودُ مراجعات لفظية للمستهلكين لبطاقات الائتمان الدقةَ التوقعية.
في معظم الحالات لا يمكن تقديم حجة قوية لصالح التعلم العميق كبديل للتحليل التقليدي للبيانات إلا إذا استطاعت المكاسب المتواضعة في التوقع أن تؤدي إلى تقليل كبير في التكاليف أو زيادة كبيرة في الأرباح.
ويناسب التعلم العميق بشكل خاص تحديد الأنماط في البيانات غير المتجانسة وغير المهيكلة. أخيراً، مثلاً، طور بعضنا نمذجة مستندة إلى التعلم العميق لمساعدة مصممي السيارات على توقع كيفية تفاعل المستهلكين مع النمذجات الأولية التي لا تزال في طور التصميم إلى جانب توليد أفكار لمنتجات جديدة أيضا.ً2
A. Burnap, J.R. Hauser, and A. Timoshenko, “Design and Evaluation of Product Aesthetics: A Human-Machine Hybrid Approach,” working paper, MIT Sloan School of Management, Cambridge, Massachusetts, July 2019.
P. Dhillon and S. Aral, “Modeling Dynamic User وفي حالة أخرى، ابتكر باحثون نمذجة للسلوك الاستهلاكي الجديد لدى العملاء لتوقع العادات المستقبلية للمشاهدة Viewing habits.3
Interests: A Neural Network Approach,” working paper, MIT Sloan School of Management, Cambridge, Massachusetts, 2019. وفي الآونة الأخيرة بدأت شركات باستخدام التعلم العميق لتحليل صور الملابس ذات العلامات التجارية التي ينشرها المستهلكون على مواقع التواصل الاجتماعي وتوقع البنود التي سيرجعها العملاء بأعلى معدلات والكوبونات التي ستولد معظم الأرباح.4
L. Liu, D. Dzyabura, and N. Mizik, “Visual Listening In: Extracting Brand Image Portrayed on Social Media,” working paper, Social Science Research Network, 2019. ويسمح ذلك للمديرين بوضع سياسات أفضل لإرجاع المنتجات واستراتيجيات حسم أكثر فاعلية. وأظهرت دراسة سابقة أجراها بعضنا أن أساليب التعلم العميق ساعدت الشركات على وصف المحتوى الذي ولّده المستخدمون بكفاءة أكبر، ومن ثم ركزت جهود المحللين على مراجعات مفيدة جداً حددت احتياجات العملاء بتكاليف أقل بكثير من الأساليب التقليدية.5
A. Timoshenko and J.R. Hauser, “Identifying Customer Needs From User-Generated Content,” Marketing Science 38, no. 1 (January-February 2019): 1-20.
وتبرز فرص جديدة لتطبيقات التعلم العميق بشكل مستمر. فالتعلم العميق يشجع التجريب ويمكّن تجارب أ/ب من التكيف في الوقت الفعلي، ويمكّن من الضبط والتعديل عند ورود النتائج. وطورنا بالفعل نهجاً بسيطاً بالذكاء الاصطناعي يتكيف مع الصور والمحتوى الخاصين بالإعلانات عبر الإنترنت ليتطابق مع الأسلوب الإدراكي للمستهلك، ويصمم أنظمة تجريبية فاعلة في الوقت الفعلي من أجل المعرفة التكيفية للنسخة الإعلانية المثلى لكل مجموعة من العملاء. وتتيح النماذج الإحصائية الحالية للشركات توجيه الإعلانات إلى المستهلكين عبر الإنترنت. ولكن نظام الذكاء الاصطناعي يسمح للمسوقين بتكييف نسخة الإعلان مع أساليب الإدراك والتواصل الخاصة بالأفراد، وتخصيص الصور والرسوم البيانية لتناسب تفضيلاتهم البصرية، ودمج الإحصائيات والأدلة الأخرى لتتواءم مع أساليبهم الخاصة باتخاذ القرار. وتُظهر التطبيقات نتائج واعدة ومن المحتمل أن تحقق نتائج أفضل مع توفر خوارزميات جديدة تعتمد على التعلم العميق وقواعد بيانات أكثر شمولاً.6
G. Urban, J. Hauser, G. Liberali, et al., “Morph the Web to Build Empathy, Trust, and Sales,” MIT Sloan Management Review 50, no. 4 (summer 2009): 53-61.
الآثار المترتبة للشركات
ماذا يعني كل هذا بالنسبة إلى الشركات؟ بناءً على تجربتنا، نرى العديد من الخلاصات لمديري التسويق:
1. كونوا متيقظين للفرص المستقبلية Be alert to the future opportunities. ستظل الأنظمة المستندة إلى الإحصائيات تؤدي دوراً حاسماً في تحليلات التسويق، لكن ليس من المبكر جدّاً تخيل مدى قدرة التعلم العميق على تعزيز العمليات الحالية وتمكين الحلول للمشكلات الجديدة. وتتضمن المجالات ذات الاحتمالات المرتفعة إعداد الميزانية والجدولة لترويج أكثر تعقيداً، واستهدافاً أكثر تقدماً للعملاء، وتطويراً أدق لمنتجات جديدة.
2. أنشئوا قواعد بيانات غنية Create rich databases. من المرجح أن يؤدي دمج العديد من مصادر البيانات وأنواعها إلى تقدم كبير في تحليل الاستجابة وتحسين موارد التسويق. ويُتوقَّع أن تشمل أكبر تكاليف التعلم العميق الحصول على البيانات وإنشاء قواعد البيانات وتكاملها. وفي دراستنا لاختيار بطاقة الائتمان، ارتبط أكثر من %50 من التكاليف بجمع البيانات، وتصنيفها، وتنظيفها. لذلك يجب على المديرين الذين يرون أن منافع التعلم العميق تستحق الاستكشاف في أعمالهم أن يستثمروا في برمجيات لجمع تعليقات المستهلكين من مواقعهم الشبكية، وأمازون، وتويتر، وإنستغرام، إضافة إلى سجلات لتدفقات النقرات الفردية المتعلقة بقرارات العملاء في مجال البحث والشراء.
3. ابنوا القدرة من خلال التدريب والموظفين الجدد Build capability through training and new hires. للاستفادة من الفرص في التعلم العميق، ستحتاج إلى خبراء داخليين قادرين على العمل مع قواعد البيانات الخاصة بكم. وهؤلاء سيحتاجون إلى معرفة كيفية تحقيق الاستفادة القصوى من استخدام البيانات الغنية وتوظيفها لحل مشكلات التسويق التي لم يتم حلها من قبل وتشكيل تبصرات استراتيجية جديدة. وتتطلب معالجة البيانات الغنية معرفة متقدمة في الذكاء الاصطناعي والميزانيات لتوظيف الاستشاريين لزيادة الموظفين الداخليين الحاليين.
4. ضعوا خططاً للتجريب Develop plans for experimentation. إضافة إلى استخدام التعلم العميق لإجراء تجارب أفضل وأكثر كفاءة من نوع أ/ب، يمكنكم أيضاً استخدامه لاختبار متغيرات تسويقية جديدة. وقد تكمن أكبر الإمكانات في التجارب المركزة التي تستخدم متغيرات مختلفة بشكل منهجي من أجل قياس الاستجابة. وسيكون آخر التطورات هو تطبيق محفزات مختلفة في الوقت الفعلي لكل مستخدم. وبعد ذلك يمكن تحليل التجارب عبر أساليب التعلم العميق.
أفكار حول المستقبل Thoughts About the Future
على الرغم من تكاليف التنفيذ وتحدياته، فنحن متفائلون بإمكانات التعلم العميق في وضع ممارسات تسويق متطوّرة من خلال تمكين تحليل قواعد البيانات الغنية والتجريب في الوقت الفعلي. ويستطيع هذا التطبيق في تحليلات التسويق: (1) تحسين تقديرات استجابة السوق للمساعدة على زيادة العائد على الربح ROI في مجال الأرباح والتسويق، و(2) الكشف عن فرص جديدة لتطوير المنتجات، و(3) السماح بتصميم أكثر استهدافاً للمنتجات، والتوزيع، والترويج، وتحسين الوسائط. وعلى الرغم من توفر مكاسب هامشية فقط مع البيانات القديمة والتحليلات التقليدية، ستبرر التحسيناتُ في الدقة والتبصر، في العديد من التطبيقات التحليلية الجديدة، الاستثمارَ في تكنولوجيا التعلم العميق وبياناته.
شكر وتقدير
نود أن نشكر بنك سوروغا Suruga Bank ومبادرة معهد ماساتشوستس للتكنولوجيا Massachusetts Institute of Technology في الاقتصاد الرقمي على دعمهم التمويلي، ونيرد واليت وكومسكور Comscore على توفير البيانات المستخدمة في الأبحاث.
المراجع
| ↑1 | For further information, see I. Goodfellow, Y. Bengio, and A. Courville, “Deep Learning” (Cambridge, Massachusetts: MIT Press, 2015); A. Géron, “Hands-On Machine Learning With Scikit-Learn and TensorFlow” (Sebastopol, California: O’Reilly Media, 2017); and R.S. Sutton and A.G. Barto, “Reinforcement Learning: An Introduction” (Cambridge, Massachusetts: MIT Press, 2018). |
|---|---|
| ↑2 | A. Burnap, J.R. Hauser, and A. Timoshenko, “Design and Evaluation of Product Aesthetics: A Human-Machine Hybrid Approach,” working paper, MIT Sloan School of Management, Cambridge, Massachusetts, July 2019. P. Dhillon and S. Aral, “Modeling Dynamic User |
| ↑3 | Interests: A Neural Network Approach,” working paper, MIT Sloan School of Management, Cambridge, Massachusetts, 2019. |
| ↑4 | L. Liu, D. Dzyabura, and N. Mizik, “Visual Listening In: Extracting Brand Image Portrayed on Social Media,” working paper, Social Science Research Network, 2019. |
| ↑5 | A. Timoshenko and J.R. Hauser, “Identifying Customer Needs From User-Generated Content,” Marketing Science 38, no. 1 (January-February 2019): 1-20. |
| ↑6 | G. Urban, J. Hauser, G. Liberali, et al., “Morph the Web to Build Empathy, Trust, and Sales,” MIT Sloan Management Review 50, no. 4 (summer 2009): 53-61. |